Signal Flow and Voicing
This section explains the exact routing of the Signal Flow in MASSIVE. We recommend reading this part if you really want to understand how MASSIVE works, as it shows exactly how all of the various parts of the synthesizer are connected and can affect each other.
The signal flow in MASSIVE is relatively easy to understand, as it follows the well-known paradigm of a subtractive synthesizer. It is extremely flexible and contains some powerful additional features as well. The Signal Flow is pictured in the Routing Page of the Center Window:
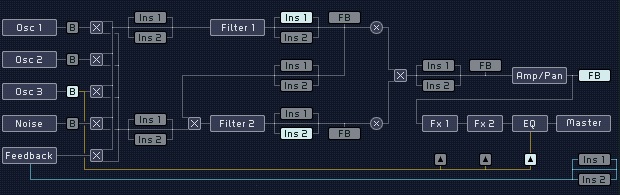
Here is a basic description of how it works.
Three wavetable oscillators and a noise oscillator generate four audio signals to form the basis of the sound. There is also an additional modulation oscillator that does not mix its signal into the audio signal, but is used to modulate the three main oscillators. Various modulation modes (phase modulation, ring modulation, position modulation) can be selected. Besides these modes, the modulation oscillator can also be used to modulate the filters’ frequencies. In addition, there is also a feedback bus (explained further below) that brings back part of the signal from later in the chain and mixes it back in as an input source. Have a look at section Oscillator Section for more information about these initial stages of sound generation.
These source signals are mixed down to two individual filter busses using the Routing Faders on each source. The Input Fader (labeled Ser <> Par at the top) mixes the second filter bus signal with the output of the first filter; in other words, you can crossfade between a parallel filter routing (the second filter uses an individual input bus) and a serial filter routing (the second filter uses the output of the first filter). Note that if this is set to serial and all the oscillators are routed to the f2 bus, you will hear no sound! The Filter Section outputs one combined signal to the next section, a mix of f1 and f2. See section Filter Section for details and examples of different filter routings.
After the filters, the signal is routed to the Amp Section (see section Amp Section) and the Master Effects (see section Master Effects Section). It goes first through an amplification envelope in the Amp Section, then through a pan control; then parallel voices are downmixed (more on this below). Then the signal passes through the Master Effects one at a time, then a final EQ, and finally through a Master Volume to set the global output volume.
Note that there are also a few parts of the signal flow that can be moved or changed: the Insert Effects, the Bypass Section, and the Feedback Section. The role of these modules in the signal flow is controlled in the Routing Page (see section General Pages).
The inserts are effects that can be inserted into the signal flow at various places to manipulate an audio signal. They could be applied to both filter busses individually, or between the filters with a serial setup, or to the filtered signal before it is amplified, or to feedback signal only. See section Insert Effects for more on how this works.
The Bypass control selects the output from one of the three main oscillators or the noise oscillator and routes this signal directly to the Amp Section at the end of the signal chain, where it is added to the downmixed signal at various places: after the Pan, or after FX1 or FX2 in the Master Effects Section. This can be used to keep a direct, raw signal mixed in the output, such as a subbass. There is more information about this in section Bypass Section.
The Feedback control lets you route an audio signal from a number of different points in the chain (selectable in the Routing Page) and route it back to the Feedback Section. Feedback can be used to alter a filter’s frequency characteristics, to saturate/distort the sound, or to use feedback with delay signals and so on. (See section Feedback Section for details.)
Tightly linked to signal flow is the voicing structure of MASSIVE, which specifies how the synthesizer’s voices are handled. If you want to play chords, you need several voices, one per note, just as when playing a chord on a keyboard, you need multiple fingers to press all keys simultaneously. Each of MASSIVE’s voices can generate one of the notes within the chord, i.e. each voice can have its individual pitch and starting point. However, all voices share the same structure and general settings as adjusted in the User Interface.
You can see the number of voices when looking at the Navigation Bar: the number of voices currently being used is displayed first, and the maximum number of voices available is displayed second. (You can adjust this maximum number within the Voicing Page of the Center Window.)
The sound of each voice is computed independently from all others until the signal is downmixed to generate a stereo output signal (like a downmix in a multi-track sequencer). This downmix process takes place just before the signal is routed through the Master Effects. This is particularly important as the tube effects, for example, would sound different and less interesting if the downmix took place after the effect.
In the Voicing Page you can also find the Unisono Control. This can enable you to trigger several internal voices when triggering one note with the MIDI keyboard. This is analogous to the situation in an orchestra when several violins are playing the same notes, or when several singers sing the same part in a choir. If all singers sang exactly similarly, the sound would only become louder, but as each singer actually sings just a bit differently, the actual sound becomes richer and more complex when more singers are added. This is also true for MASSIVE: you can use multiple voices for one note, and can, for instance, detune each voice slightly to create a choir-like effect. All this can be adjusted within the Voicing Page of the Center Window (see section General Pages).
Note
Please note that each voice used needs to be computed independently by the computer: the more voices you use, the heavier the CPU load. Also note that due to internal optimizations, the CPU load is minimized when the number of voices can be exactly divided by four, i.e. it is preferable to use 4, 8, 12 etc. voices.